Web crawlers, also called spiders, are bots operated by search engines, like Google, to automatically scan websites and index them. The first step to indexing webpages is accessing robots.txt files by the crawlers and reading the instructions which define which website areas are allowed or disallowed to be crawled.
Knowing about the functionalities of robots.txt files and methods to change the instructions for crawlers helps in understanding new aspects of website optimization and security.
Table of Contents
- What Is a Robots.txt File?
- Why Robots.txt Files Are Important for Website SEO
- What You Can Do with Robots.txt
- Best Practices for Using Robots.txt Files
- How Do Popular WordPress Sites Use Their Robots.txt Files?
- Summary
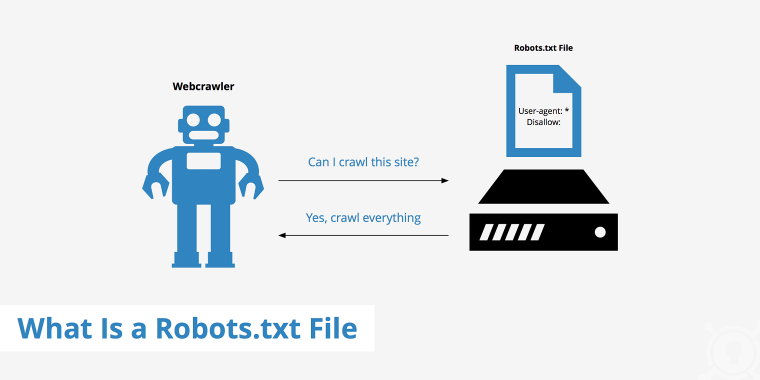
What Is a Robots.txt File?
Robots.txt is a configuration file that provides instructions for bots (mostly search engine crawlers) that try to access certain pages or sections of the website. It is located in your root WordPress directory, the first file the crawlers see when entering the site.
To see this file’s instructions, the search engine bots must support the Robots Exclusion Protocol (REP). This protocol is a standard explaining how the bots (web robots) interact with websites. In practice, it makes them download a robots.txt file and parse the information about which areas of the site they must crawl.
However, not all websites need to have a robots.txt file because search engines usually can find and index all the important web pages, and they will not present unimportant pages in search results. Having a robots.txt file is not a reliable mechanism to keep your web pages off Google for two reasons:
- The robots.txt file contains instructions that prevent bots from crawling, not indexing pages. The page can be indexed if external links lead to it, even if bots don’t crawl it.
- Not all bots strictly follow the rules in the robots.txt file, even though the most important ones, Google, Bing, and Yahoo bots, obey the REP standards.
That said, there are other ways to prevent your WordPress page from appearing in search engine results, such as adding a noindex meta tag to a page or protecting it with a password.
Why Robots.txt Files Are Important for Website SEO
Because a robots.txt file allows you to manage search robots, its instructions significantly impact SEO (Search Engine Optimization). The proper directives can provide your WordPress site with quite a few benefits.
Well-written instructions can deny access to bad bots mitigating their negative impact on overall website speed. However, you must remember that malicious bots or email scrapers may ignore your directives or even scan the robots.txt file to determine which areas of your site to attack first. It’s better not to rely on the robots.txt file as your only security tool and use good security plugins if you’re experiencing problems with bad bots.
Even good robots’ activity can overload servers or even cause them to crash. Robots.txt can contain instructions for a crawl delay to stop crawlers from loading too many pieces of data at once, weighing down the servers.
Improved robots.txt directives ensure that your site’s crawl quota is used with maximum effect and that the crawl budget for Google bots is not exceeded. Because there’s a maximum number of times bots can crawl the site in a certain time, it’s beneficial if they focus on genuinely relevant sections. You can achieve it by banning unimportant pages.
What You Can Do with Robots.txt
Like all other website files, the robots.txt file is stored on the web server, and you can usually view it by typing the site’s homepage URL followed by /robots.txt like www.anysite.com/robots.txt. The file isn’t linked anywhere on the site, so it is unlikely that users will access it accidentally. Instead, most search crawlers that adhere to REP protocol will look for this file before they crawl the website.
How to create and edit robots.txt
WordPress automatically generates a virtual robots.txt file for your website and saves it in the root directory. By default, such a file contains the following directives:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
However, if you’d like to modify instructions for search robots, you need to create a real robots.txt file and overwrite the old file. There are two easy ways to do this:
- Create an empty .txt file and save it on your computer as robots.txt. Upload it to your server using File Transfer Protocol.
- Use one of the SEO WordPress plugins that have a robots.txt managing feature.
Adding rules to robots.txt
Now that you know about the benefits of the robots.txt file and how you can edit it, let’s see what directives this file can contain and what results it can achieve:
- user-agent: identifies the crawler (you can find the names of crawlers in the robots database);
- disallow: denies access to certain directories or web pages;
- allow: allows crawling of certain directories and web pages;
- sitemap: displays sitemap’s location;
- crawl-delay: displays the number of milliseconds each bot has to wait between requests;
- *: denotes any number of items;
- $: denotes the end of the line.
The instructions in robots.txt always consist of two parts: the part that specifies which robots the following instruction applies to, and the instruction itself. Look at the example provided above again:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
The asterisk sign is a “wild card,” meaning the instructions apply to all bots who happen to stop by. So all bots are prevented from crawling content in the /wp-admin/ directory. The next row overwrites the previous rule allowing access to the /wp-admin/admin-ajax.php file.
Best Practices for Using Robots.txt Files
Your business needs to attract an audience to come to your site. Use your knowledge about robots.txt and turn it into an effective tool to improve SEO and promote your products and services. Knowing about what robots.txt can and can’t do is already a good start to build on your site’s rankings. Here are some rules to remember to ensure you take the most out of robots.txt and don’t risk your site’s safety.
- Don’t use robots.txt to prevent access to sensitive data, such as personal information, from appearing in search engines’ results. External sources may contain links to your page and make it indexable without you knowing it.
- The links on blocked pages won’t be indexed either, which means such links will not receive link equity from your pages.
- It is better to disallow directories, not pages if you want to hide sensitive content. Remember that some malware bots may look for sensitive pages to focus on in the robots.txt file.
- You can use the disallow command to keep crawlers off the duplicate pages, for example, identical content in different languages. However, the users won’t see them in search engines, which won’t help your website rank.
- Use proper syntax when editing the robots.txt file – even the slightest mistake can make the whole site unindexable.
- After you create and upload the robots.txt file, ensure your coding is right by navigating to Google Testing Tool and following the directions.
- It is generally a good practice to include the location of a sitemap at the end of robots.txt instructions to ensure the crawl bots don’t miss anything important. The sitemap URL may be located on a different server than the robots.txt file, and you can include more than one sitemap.
How Do Popular WordPress Sites Use Their Robots.txt Files?
Let’s see how popular websites built with WordPress handle their robots.txt files.
observer.com

The Observer uses the default WordPress robots.txt instructions disallowing all bots from crawling /wp-admin/ directory except for the /wp-admin/admin-ajax.php file and including locations of their sitemap files.
rollingstone.com
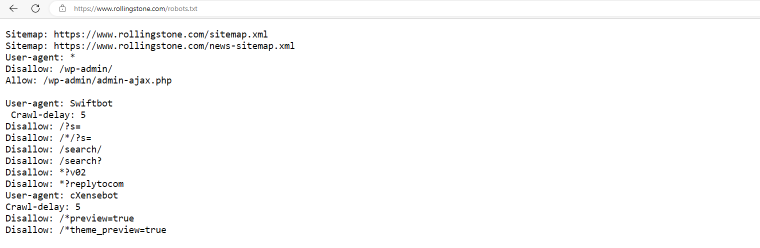
The Rolling Stone website has a robots.txt file that includes sitemaps, default restrictions for all bots to crawl /wp-admin/ files, and specific instructions for Swiftbots and cXensebots not to crawl certain pages and have a five-millisecond delay between requests.
vogue.com
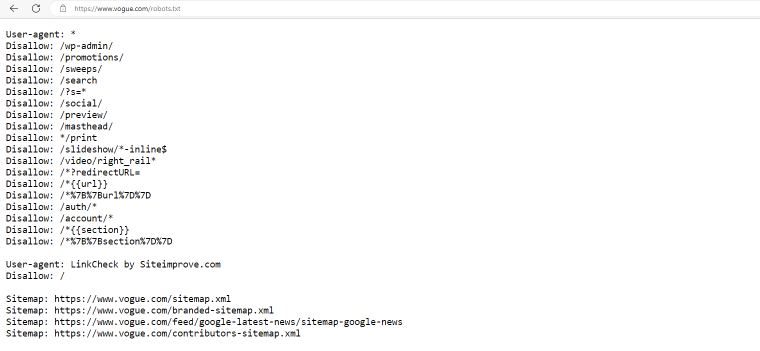
Vogue.com denies access to a larger list of pages to all bots and restricts access to the entire website to Linkcheck bots.
katyperry.com

Here’s an example of how an SEO plugin modifies a robots.txt file. In this case, it’s the work of the Yoast plugin, and all bots are allowed to crawl the entire site. The lines starting with a ‘#’ sign are not directives but comments.
crocoblock.com
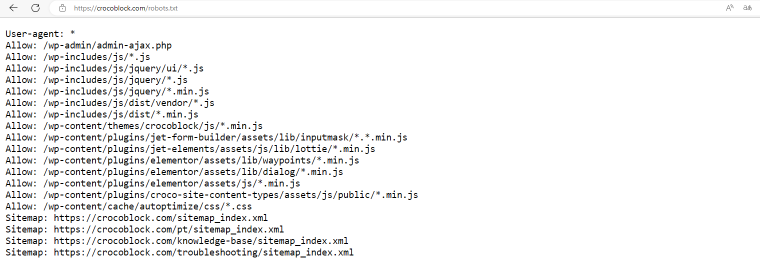
The robots.txt file for the Crocoblock website puts no restrictions on web crawlers. Instead, we indicated the files we wanted the bots to focus on.
Summary
The WordPress robots.txt file is located in the root directory of every site, and it is the first place web crawlers visit to find instructions about which parts of the website should or shouldn’t be assessed, indexed, and ranked. Being able to create and edit your own robots.txt file may help optimize your website for SEO and keep the good bots under control.
If you want to avoid security risks, adhere to the best practices when editing robots.txt files, and learn what this tool can and can’t be used for.


{kind=link}